
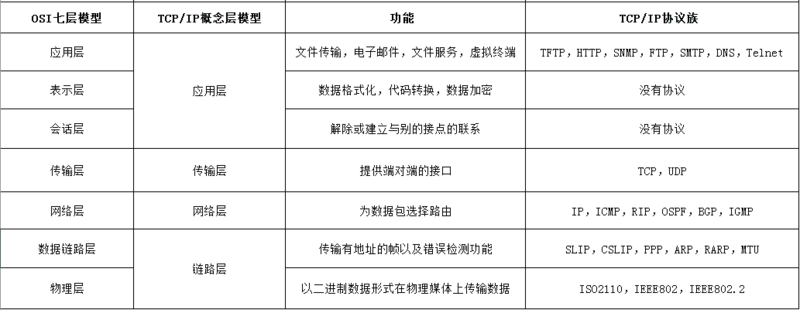
| OSI中的层 | 功能 | TCP/IP协议族 |
|---|---|---|
| 7 应用层 | 文件传输,电子邮件,文件服务,虚拟终端 | HTTP,FTP,SMTP,DNS,Telnet ,SNMP,TFTP等等 |
| 6 表示层 | 数据格式化,代码转换,数据加密 | 没有协议 |
| 5 会话层 | 解除或建立与别的接点的联系 | 没有协议 |
| 4 传输层 | 提供端对端的接口 | TCP,UDP |
| 3 网络层 | 为数据包选择路由 | IP,ICMP,OSPF,EIGRP,IGMP |
| 2 数据链路层 | 传输有地址的帧以及错误检测功能 | SLIP,CSLIP,PPP,MTU |
| 1 物理层 | 以二进制数据形式在物理媒体上传输数据 | ISO2110,IEEE802,IEEE802.2 |
TCP/IP
TCP/IP 是互联网相关的各类协议族的总称,比如:TCP,UDP,IP,FTP,HTTP,ICMP,SMTP 等都属于 TCP/IP 族内的协议。
TCP/IP 是因特网的通信协议。
TCP/IP 指传输控制协议/网际协议(Transmission Control Protocol / Internet Protocol)。
TCP/IP 定义了电子设备(比如计算机)如何连入因特网,以及数据如何在它们之间传输的标准。
TCP 负责将数据分割并装入 IP 包,然后在它们到达的时候重新组合它们。IP 负责将包发送至接受者。
IP 负责在因特网上发送和接收数据包。 TCP/UDP区别
TCP (传输控制协议) - 应用程序之间通信
- 面向连接的、可靠的、基于字节流的传输层通信协议
- 三次握手
- 第一次:客户端向服务端发送连接请求报文段。该报文段中包含自身的数据通讯初始序号。请求发送后,客户端便进入 SYN-SENT 状态。
- 第二次:服务端收到连接请求报文段后,如果同意连接,则会发送一个应答,该应答中也会包含自身的数据通讯初始序号,发送完成后便进入 SYN-RECEIVED 状态。
- 第三次:当客户端收到连接同意的应答后,还要向服务端发送一个确认报文。客户端发完这个报文段后便进入 ESTABLISHED 状态,服务端收到这个应答后也进入 ESTABLISHED 状态,此时连接建立成功。
- TCP 建立连接需要三次握手
- 为了防止出现失效的连接请求报文段被服务端接收的情况,从而产生错误。
- 特点
- 面向连接:发送数据之前必须在两端建立连接“三次握手”,这样能建立可靠的连接,为数据的可靠传输打下了基础
- 仅支持单播传输,只能进行点对点的数据传输,不支持多播和广播传输
- 面向字节流:TCP不像UDP一样那样一个个报文独立地传输,而是在不保留报文边界的情况下以字节流方式进行传输。
- 可靠传输:TCP为了保证报文传输的可靠,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收然后接收端实体对已成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据(假设丢失了)将会被重传。
- 提供拥塞控制:当网络出现拥塞的时候,TCP能够减小向网络注入数据的速率和数量,缓解拥塞
- TCP提供全双工通信:TCP允许通信双方的应用程序在任何时候都能发送数据,因为TCP连接的两端都设有缓存,用来临时存放双向通信的数据。当然,TCP可以立即发送一个数据段,也可以缓存一段时间以便一次发送更多的数据段(最大的数据段大小取决于MSS)
UDP (用户数据报协议) - 应用程序之间的简单通信 无连接的协议
- 面向无连接,不进行握手
- 有单播,多播,广播的功能 支持一对多,多对多,多对一的方式,也就是说 UDP 提供了单播,多播,广播的功能
- UDP是面向报文的
- 发送方的UDP对应用程序交下来的报文,在添加首部后就向下交付IP层。UDP对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界。因此,应用程序必须选择合适大小的报文
- 不可靠性(网络条件不好的情况下可能会导致丢包)
- 头部开销小,传输数据报文时是很高效的
- 只是数据报文的搬运工,不提供数据包分组、组装和不能对数据包进行排序的缺点
- (UDP只会把想发的数据报文一股脑的丢给对方,并不在意数据有无安全完整到达)
- 优点也很明显,在某些实时性要求高的场景(比如电话会议)就需要使用 UDP 而不是 TCP
IP (网际协议) - 计算机之间的通信
ICMP (因特网消息控制协议) - 针对错误和状态
DHCP (动态主机配置协议) - 针对动态寻址
SMTP - 简单邮件传输协议 UDP TCP 是否连接 无连接 面向连接 是否可靠 不可靠传输,不使用流量控制和拥塞控制 可靠传输,使用流量控制和拥塞控制 连接对象个数 支持一对一,一对多,多对一和多对多交互通信 只能是一对一通信 传输方式 面向报文 面向字节流 首部开销 首部开销小,仅8字节 首部最小20字节,最大60字节 适用场景 适用于实时应用(IP电话、视频会议、直播等) 适用于要求可靠传输的应用,例如文件传输 链路层:负责封装和解封装IP报文,发送和接受ARP/RARP报文等。
网络层:负责路由以及把分组报文发送给目标网络或主机。
传输层:负责对报文进行分组和重组,并以TCP或UDP协议格式封装报文。
应用层:负责向用户提供应用程序,比如HTTP、FTP、Telnet、DNS、SMTP等。
HTTP
超文本传输协议(Hyper Text Transfer Protocol) 1. 一种用于分布式、协作式和超媒体信息系统的**应用层协议** 2. HTTP是一个客户端和服务端请求和应答的标准 3. HTTP工作原理采用了请求/响应模型
客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据
服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
- 是无状态(stateless)协议,即不保存状态,
- GET,HEAD,POST,PUT,DELETE,TRACE,OPTIONS,CONNECT 200 OK:表示从客户端发送给服务器的请求被正常处理并返回; 301 Moved Permanently:永久性重定向,表示请求的资源被分配了新的URL,之后应使用更改的URL; 302 Found:临时性重定向,表示请求的资源被分配了新的URL,希望本次访问使用新的URL; 400 Bad Request:表示请求报文中存在语法错误; 401 Unauthorized:未经许可,需要通过HTTP认证; 403 Forbidden:服务器拒绝该次访问(访问权限出现问题) 404 Not Found:表示服务器上无法找到请求的资源,除此之外,也可以在服务器拒绝请求但不想给拒绝原因时使用; 500 Inter Server Error:表示服务器在执行请求时发生了错误,也有可能是web应用存在的bug或某些临时的错误时; 503 Server Unavailable:表示服务器暂时处于超负载或正在进行停机维护,无法处理请求;
[HTTP状态码详解状态查询](https://www.code404.icu/37.html) 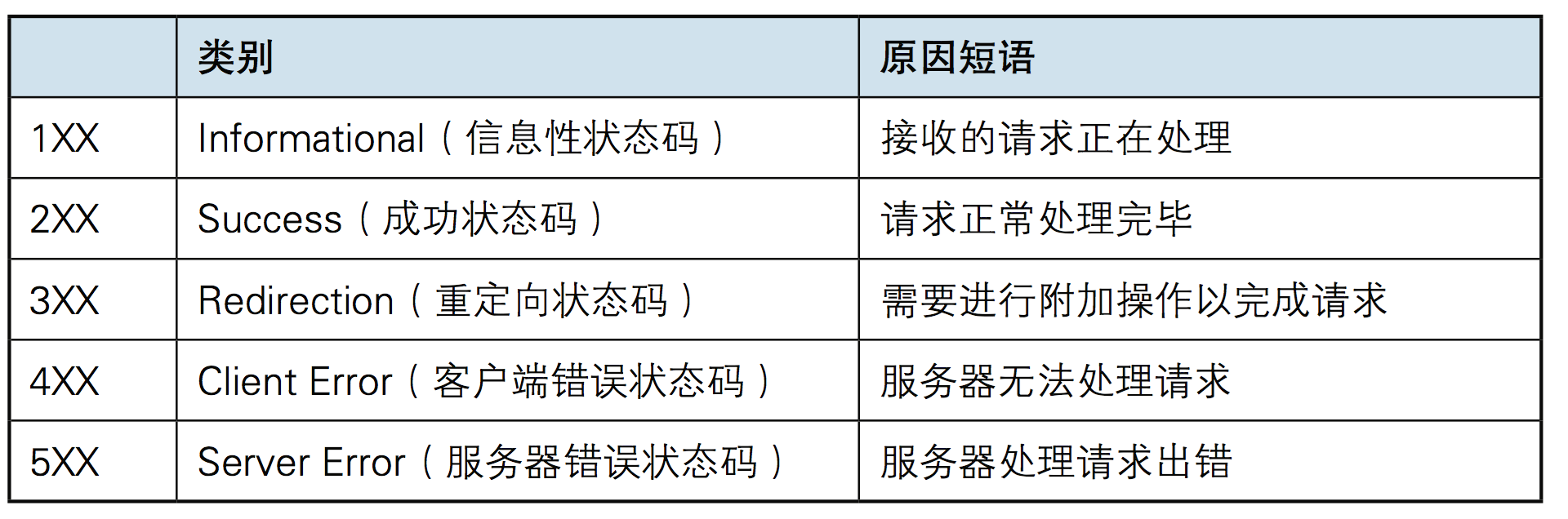 #### 浏览器地址栏键入URL- 浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
- 解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
- 浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
- 服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
- 释放 TCP连接;
- 浏览器将该 html 文本并显示内容;
#### 1.php是什么,原理及运行机制 php(**HyPertext Preprocessor**),**超文本处理器**,它是一种跨平台、开源、免费的**脚本语言** Hypertext preprocessor #### 生命周期 模块初始化阶段、请求初始化阶段、脚本执行阶段、请求关闭阶段、模块关闭阶段 #### 数据类型 八大数据类型 四个标量类型: 布尔型、字符串型、整型、浮点型 两个复合类型: 数组型、对象型 两个特殊类型 资源型和null 资源是一种特殊的变量类型,保存了到外部资源的一个引用:如打开文件、数据库连接、图形画布区域等 #### 面向对象 OOP:Object Oriented Programming 面向过程是具体化的,流程化的,解决一个问题,你需要一步一步的分析,一步一步的实现 面向对象是模型化的,你只需抽象出一个类,这是一个封闭的盒子,在这里你拥有数据也拥有解决问题的方法。 多人合作方便,减少代码冗余,灵活度高;代码可重用;可扩展性强。 三大特征:封装、继承、多态 面向过程: 优点:性能比面向对象好,因为类调用时需要实例化,开销比较大,比较消耗资源。 缺点:不易维护、不易复用、不易扩展. 优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护 . 缺点:性能比面向过程差 五大基本原则: 1、单一职责原则SRP(Single Responsibility Principle) 类的功能要单一,不能包罗万象,跟杂货铺似的。 2、开放封闭原则OCP(Open-Close Principle) 一个模块对于拓展是开放的,对于修改是封闭的,想要增加功能热烈欢迎,想要修改,哼,一万个不乐意。 3、里式替换原则LSP(the Liskov Substitution Principle LSP) 子类可以替换父类出现在父类能够出现的任何地方。比如你能代表你爸去你姥姥家干活。哈哈~~ 4、依赖倒置原则DIP(the Dependency Inversion Principle DIP) 高层次的模块不应该依赖于低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象。就是你出国要说你是中国人,而不能说你是哪个村子的。比如说中国人是抽象的,下面有具体的xx省,xx市,xx县。你要依赖的是抽象的中国人,而不是你是xx村的。 5、接口分离原则ISP(the Interface Segregation Principle ISP) 设计时采用多个与特定客户类有关的接口比采用一个通用的接口要好。就比如一个手机拥有打电话,看视频,玩游戏等功能,把这几个功能拆分成不同的接口,比在一个接口里要好的多。 #### 抽象类和接口- 对接口的继承使用implements,抽象类使用extends.
- 接口中不可以声明变量,但可以声明类常量.抽象类中可以声明各种变量
- 接口没有构造函数,抽象类可以有
- 接口中的方法默认为public,抽象类中的方法可以用public,protected,private修饰
- 一个类可以继承多个接口,但只能继承一个抽象类
require,include
require:文件不存在时,致命的错误终止执行,无返回值,(可能因为如此require的速度比include快) include:文件不存在时,警告,有返回值echo/print/print_r/var_dump
echo :语句,输出一个或者多个字符串 print :语句,与echo最主要的区别: print 仅支持一个参数,并总是返回 1 print_r :函数,可打印对象、数组,如果第二参数为 true 则不输出结果,而是将结果字符串赋值给一个变量,false 则直接输出结果 var_dump :函数,结构类型与值等详细信息,没有返回值,支持多个参数define和const的区别
const PATH = 'local/user'; define('PATH','local/user',true);- const是关键字,语言结构;define是函数
- const大小写敏感,define可通过设置第三参数改变大小写敏感
- const可在类中使用,define不能
- const不能在条件语句中定义常量
- const采用普通的常量名称,define可以采用表达式作为名称
#### get和post- get只接受ASCLL字符,而post没有限制(参数的数据类型)
- 浏览器和web服务会限制get在URl中传递的参数有长度限制,而post没有
HTTP协议并未规定get和post的长度限制
不同浏览器限制最大长度字符不一样
- get请求会被浏览器主动cache,而post不会除非手动设置
- get在浏览器回退时无请求的,而post会再次请求
- get参数通过URl传递,post放在request body中
- get请求只能进行url编码,而post支持多种编码方式
- get比post快
post请求包含更多的请求头,(如content-type),但这影响不了多少,
(这是错误的)post在真正接受接受数据之前会先将请求头发送给服务器进行确认,然后才是真正的发送数据。在tcp第三次握手时,get请求头比较小,所以http会在此时进行第一次数据发送并返回200 OK响应,而post此时服务器返回100 Continue响应,之后才发送数据get请求浏览器会把http header和data一并发送出去,但post的body 就是紧随在 header 后面发送的 8.相对而言get更不安全,
这里的安全是相对性
get提交的数据都将显示到url上
页面会被浏览器缓存,其他人查看历史记录会看到提交的数据
get提交数据还可能会造成Cross-site request forgery攻击
#### [cookie和session](https://www.cnblogs.com/l199616j/p/11195667.html) 1. cookie数据存放在客户的浏览器上,session数据放在服务器上 2. cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗虽然cookie不安全,但是可以加密
一定要设置失效时间,要不然浏览器关闭就消失了
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie
Session信息是存放在server端,但session id是存放在client cookie的,当然php的session存放方法是多样化的,这样就算禁用cookie一样可以跟踪
Cookie是完全保持在客户端的如:IE firefox 当客户端禁止cookie时将不能再使用
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。(Session对象没有对存储的数据量的限制,其中可以保存更为复杂的数据类型)
数据库相关
数据库三范式
第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余。
四种常见的索引类型
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针
- 普通索引:使用字段关键字建立的索引,主要是提高查询速度;允许数据重复和NULL
- 主键索引:一张表里面不能有多个主键索引,不能有NULL,不能重复
- 唯一索引:数据唯一不重复,数据内容里面能否为 null,在一张表里面,是可 以添加多个唯一索引。
- 全文索引:全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
主键、外键和索引的区别
定义 主键--唯一标识一条记录,不能有重复的,不允许为空 外键--表的外键是另一表的主键, 外键可以有重复的, 可以是空值 索引--该字段没有重复值,但可以有一个空值
作用 主键--用来保证数据完整性 外键--用来和其他表建立联系用的 索引--是提高查询排序的速度
个数 主键--主键只能有一个 外键--一个表可以有多个外键 索引--一个表可以有多个唯一索引
事务四大特性
原子性,要么执行,要么不执行
隔离性,所有操作全部执行完以前其它会话不能看到过程
一致性,事务前后,数据总额一致
持久性,一旦事务提交,对数据的改变就是永久的 引擎 特性 缺点 MYISAM 不支持外键,表锁,插入数据时,锁定整个表,查表总行数时,不需要全表扫描 不能在表损坏后恢复数据 INNODB 支持外键,表锁,行锁,查表总行数时,全表扫描 php mysql_num_rows() 与 mysql_affected_rows()
返回结果集中行的数目, mysql_num_rows() 此命令仅对 SELECT 语句有效, 要取得insert , update , 或者delete查询所影响到的行的数目,用mysql_affected_rows().
索引,主键,唯一索引,联合索引 的区别
- 索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。
- 主键索引(Primary Key): 数据表的主键列使用的就是主键索引。一张数据表有只能有一个主键,并且主键不能为null,不能重复。
- 唯一索引(Unique Key) :唯一索引也是一种约束。唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。也就是说,唯一索引可以保证数据记录的唯一性。
- 普通索引 :由关键字 KEY 或 INDEX 定义的索引的唯一任务是加快对数据的访问速度,一张表允许创建多个普通索引,并允许数据重复和NULL。
- 前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
- 全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。 主键,是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯 一标识一条记录,使用关键字 PRIMARY KEY 来创建。
索引可以覆盖多个数据列,如像 INDEX(columnA, columnB)索引,这就是联合索引。
索引可以极大的提高数据的查询速度,但是会降低插入、删除、更新表的速度, 因为在执行这些写操作时,还要操作索引文件。
php性能优化
1. 尽可能的使用PHP的内置方法,~~尽量静态化~~,及时销毁变量 2. 使用Json替代xml 3. 使用缓存技术 4. 减少不必要的计算,减少不必要的类 当一个变量会被多次使用时,一开始就计算好,肯定要比每次使用时都计算一遍要更高效。 5. 使用isset()和empty() 与count()、strlen()和sizeof()函数相比,isset()对于检测一个变量是否为空等场景更加简单和高效。 6. 在生产环境关闭用作调试的相关代码及错误报告 7. 及时关闭数据库连接,减少数据库及文件操作 8. 使用聚合函数减少数据库查询 9. 使用强大的字符串操作函数 举个例子,str_replace()比preg_replace()要快,而strtr()函数则比str_replace()函数快四倍 10. 尽量使用单引号 11. 尝试使用恒等运算符=== 12. 开启压缩gzipnginx
Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器
Pro Git(中文版)
排序
1. 冒泡排序:重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成 2. 快速排序:首先设定一个分界值,通过该分界值将数组分成左右两部分 3. 插入排序:插入排序算法是基于某序列已经有序排列的情况下,通过一次插入一个元素的方式按照原有排序方式增加元素 4. 选择排序:选择排序算法的基本思路是为每一个位置选择当前最小的元素 5. 归并排序防止超卖_mysql处理高并发
防止超卖:
- 若,小型应用,并发量小,数据库完全可以胜任并发的情况下:
- 乐观锁:其实就有是在更新数据的时候加多几个where 条件 这样能够有效的防止多用户同时对一条数据进行操作 UPDATE FROM goods SET num = num - 1 WHERE goodsid = 2 AND num > 0
strlen()与mb_strlen()都是用于获取字符串长度的,不同之处在于mb_strlen()第二个参数可以用于指定字符编码 PHP截取字符串的函数有:substr() / mb_substr() / mb_strcut()implode join() 函数是 implode() 函数的别名。 把数组元素组合为字符串:implode(" ",$arr);
explode 把字符串打散为数组:explode(" ",$str);
//创建多级目录的 PHP 函数 function create_dir($path,$mode){ if (is_dir($path)){ echo "该目录已经存在"; }else{ if(mkdir($path,$mode,true)){ echo "创建目录成功"; }else{ echo "创建失败"; } } } create_dir('./tp5/b/',0777);
Ftp21、ssh22、telnet23、http80、、https443
#### php的public、protected、private三种访问控制模式的区别
public: 公有类型
protected: 受保护类型
在子类中可以通过self::var调用protected方法或属性,parent::method调用父类方法
在实例中不能通过$obj->var 来调用 protected类型的方法或属性
private: 私有类型
该类型的属性或方法只能在该类中使用,在该类的实例、子类中、子类的实例中都不能调用私有类型的属性和方法
### redis
1.
避免中文乱码 : redis-cli --raw
https://www.mdaima.com/news/99.html
https://blog.csdn.net/lin123_00/article/details/107569306
https://www.cnblogs.com/zeoblog/p/6431143.html
https://www.php.cn/toutiao-415522.html
http://xkzzz.com/post/1893.html
https://blog.csdn.net/weixin_35578748/article/details/115685364
https://www.renrendoc.com/paper/115975255.html
https://www.php.cn/be/go/462608.html
https://zhuanlan.zhihu.com/p/122398882
https://blog.csdn.net/weixin_39967670/article/details/115757645
手写非递归方式二叉树遍历、TCP/IP,如何保证可靠,三次握手,socket,流量控制,UDP,常见TCP/UDP 应用协议, 网页请求过程(详细描述),HTTP(状态码),JAVA内存泄漏,线程,进程,epoll,多线程,多进程,同步异步,数据库两种引擎,分表,用户注册流程,100万用户粉丝互相订阅,链表有环判断,找环起点,1000瓶毒酒只有一瓶有毒,让囚犯试喝,最少需要几个囚犯。 先问进程和线程的区别,又问多进程程序与多线程程序的优劣,问了 Linux 常用命令,git使用非递归方式遍历二叉树,语言不限。问了一下怎么从先序、中序、构造二叉树,先序后序能不能构造出来之类的。主要还是介绍项目,项目问的很细,细到token怎么生成校验、存储、有效期,没问编程两个进程怎么使用共享内存,细节说一下进程间的通信方式方式口述快排,问了复杂度,什么是最坏情况?
1-2面主要的,感觉不是很难,但是准备不足的话,可定答不上,题目如下: 1. 索引为什么不多用; 2. 数据库和表的关系; 3. git撤回命令; 4. docker compose; 5. jwt的优点; 6. 单点登陆; 7. RESTful是啥啊? 8. socket服务端和客户端通信过程; 9. get post区别; 10. 非关系型数据库和关系型数据库的区别; 11. 事务的四大特性; 12. 什么时候不该使用索引、索引底层的数据结构?B+树做索引比红黑树好在哪里?什么是联合索引、 最左前缀匹配原则及它的原因; 13. 乐观锁 悲观锁; 14. Java static关键字; 15. python深浅复制; 16. b+树分析,优缺点; 17. 如何解决脏读; 18. 数据隔离级别、 各个级别都解决了什么问题; 19. 为什么要序列化?有哪些常见的序列化协议? 20. 事务; 21. 如何设计数据库表。
TCP/UDP 区别,TCP 如何保证可靠连接; 2. HTTPS 连接建立; 3. Python web 框架如何处理 HTTP 请求; 4. list 和 array 区别; 5. Kubernetes 的 pod 概念,如何调度,如何打通网络。
一个大文件怎么快速传输到另外一个文件,分块 并发 md5 校验 小客户端 合并 udp 考虑双方带宽 先计算
跑满一亿个qq号如何快速找到想要的信息。字典树进程通信,
sqlever怎么优化查询,mysql优化和sqlever优化一样吗。
怎么读一个大文件
JVM的啥忘记
SVN向量机(因为简历上写了DL)
redis的优化模型字典树
sql优化
AOP
多线程什么时候用
linux忘记了
数据库连接池Alibaba Druid
面试官很nice,堆栈区别,TCP三次握手和四次挥手?为什么需要四次挥手?设计题:一个很多用户的用户表应该怎样设计?设计题,由于之前没有准备过,就随便答了一下纵横分割。
1.const修饰 常量 函数 构造方法 分别会怎样 2. 大数据去重题。10亿用户,有多个用户对应一个手机号,想把这些用户找到,用什么办法。不能借用任何其他API(回头查了下用位图 惊艳到了) 3. 网络的TCP/UDP原理 区别 使用场景 4. 字节流和字符流 5. 堆和栈内存泄漏和溢出
Redis 数据类型
目前评论:0