
有时需要分析网站日志文件,统计诸如爬虫数量的需求,但大文件直接下载在编辑器中打开太卡。
以下用shell命令进行分析
以下假设日志文件名为:eyunzhu.com-access_log
统计谷歌爬虫数量的方法
#在网站日志目录下执行命令: #统计谷歌爬虫数量的方法 cat eyunzhu.com-access_log | grep 'Googlebot' | wc -l
将日志中所有IP去重复后保存到文件
# 匹配ip地址 排序后去重复 输出到文件ip_uniq.txt # uniq只能检测到邻近的重复行,所以我们要先进行排序,然后再查找重复行 cat eyunzhu.com-access_log | egrep -o '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' | sort | uniq -d > ip_uniq.txt
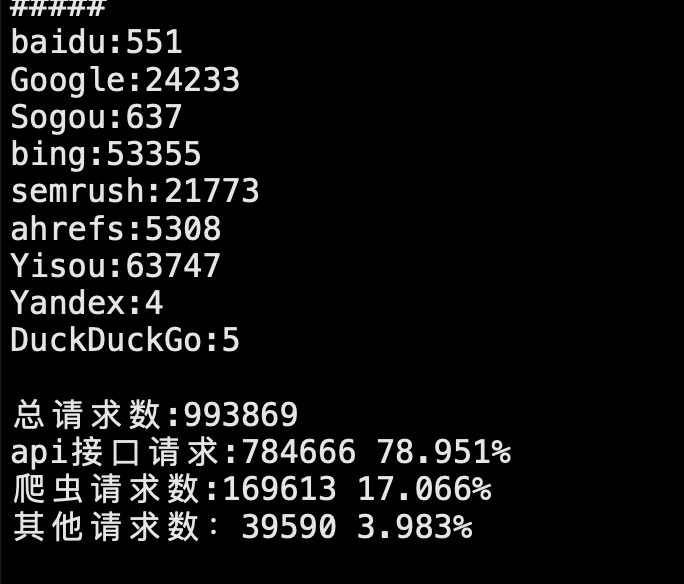
统计所有请求情况包含百度蜘蛛、谷歌蜘蛛、必应蜘蛛等及各自所占比例
# 整体命令如下: logfile=eyunzhu.com-access_log \ allRequest=`cat $logfile | wc -l`; \ apiRequest=`cat $logfile | grep '/aso'| wc -l`; \ baidu=`cat $logfile | grep 'baidu.com/search/spider' | wc -l`; \ Google=`cat $logfile | grep 'Googlebot' | wc -l`; \ Sogou=`cat $logfile | grep 'Sogou web spider' | wc -l`; \ bing=`cat $logfile | grep 'bing.com/bingbot' | wc -l`; \ semrush=`cat $logfile | grep 'semrush.com/bot' | wc -l`; \ ahrefs=`cat $logfile | grep 'ahrefs.com/robot' | wc -l`; \ Yisou=`cat $logfile | grep 'YisouSpider' | wc -l`; \ Yandex=`cat $logfile | grep 'YandexWebmaster' | wc -l`; \ DuckDuckGo=`cat $logfile | grep 'DuckDuckGo' | wc -l`; \ totalSpider=$((baidu+Google+Sogou+bing+semrush+ahrefs+Yisou+Yandex+DuckDuckGo));\ otherRequest=$(($allRequest - $apiRequest - $totalSpider));\ echo -e "#####\r\nbaidu:$baidu\r\n\ Google:$Google\r\nSogou:$Sogou\r\nbing:$bing\r\nsemrush:$semrush\r\n\ ahrefs:$ahrefs\r\nYisou:$Yisou\r\nYandex:$Yandex\r\n\ DuckDuckGo:$DuckDuckGo\r\n\r\n\ 总请求数:$allRequest\r\n\ api接口请求:$apiRequest `awk 'BEGIN{printf "%.3f%%\n",('$apiRequest'/'$allRequest')*100}'` \r\n\ 爬虫请求数:$totalSpider `awk 'BEGIN{printf "%.3f%%\n",('$totalSpider'/'$allRequest')*100}'`\r\n\ 其他请求数:$otherRequest `awk 'BEGIN{printf "%.3f%%\n",('$otherRequest'/'$allRequest')*100}'`\r\n\ \r\n#####\r\n"
执行结果如下:

目前评论:0